November elején volt az Microsoft Ignite konferencia, amelynek egyik - általam nagyon várt - bejelentése az SQL Server 2019 Big Data Cluster General Availability-be kerülése.
Az SQL Server 2019 egyfajta kiterjesztéseként, az SQL Server 2019 Big Data Cluster-ben ténylegesen megvalósul az SQL Server integrációja a Hadoop világgal /és nem csak azzal ;)/.
A Big Data Cluster az SQL Server, az Apache Spark és HDFS (Hadoop Distributed File System) kombinációja egyetlen platformon, amely képes megfelelni akár OLTP (Online Transaction Processing), akár data lake igényeknek, és nem utolsó sorban Machine Learning igényeknek is.
Bármilyen környezetben, ahol elérhető Kubernetes (K8s) cluster, a Big Data Cluster telepíthető, legyen az on-premise („földi”) vagy felhős környezet, beleértve a Microsoft saját Azure Kubernetes Services (AKS)-ét.
A teljesség igénye nélkül nézzük meg részleteiben! Kezdjük az alappillérrel, azaz a K8s-sel.
Kubernetes (K8s)
A K8s egy open-source container orchestrator rendszer, amelyet eredetileg a Google fejlesztett ki, jelenleg pedig a Cloud Native Computing Foundation égisze alatt fejlesztik tovább.
A K8s egyfajta platform konténerizált alkalmazások automatizált deployment-jéhez /ezt a szót sem vagyok hajlandó lefordítani ;)/, skálázásához, és menedzsmentjéhez.
A Kubernetes mögött az alapkoncepció egyfajta ’desired state management’, amelynek lényege, hogy a cluster egy megadott konfigurációnak (appl.yaml) megfelelően működjön, és azt futtassa a gépeken, majd ezt a kívánt állapotot megpróbálja minden esetben fenntartani. Mindezt a K8 cluster services biztosítja. Pillantsunk bele kicsit a felépítésébe!
A Kubernetes cluster gépek halmaza. Egy gép egy node. Ez lehet fizikális vagy virtuális gép is.
Egy Kubernetes cluster-ben van legalább egy dedikált master node, a többi node worker node lesz. A Kubernetes master a felelős azért, hogy szétossza a feladatokat a worker-ek között és folyamatosan monitorozza a cluster működését. A worker-ek a container host-ok, tehát konténerizált alkalmazásokat futtatnak.
A Kubernetes telepítés legkisebb elemi egysége a pod. A pod egy logikai csoportja egy vagy több container-nek illetve a hozzátartozó erőforrásnak, amely az alkalmazás futtatásához szükséges. A pod-okat (egyet vagy többet) a Kubernetes master automatikusan rendeli hozzá a node-okhoz. (Ebbe azért beavatkozhatunk kicsit, ha úgy érezzük…)
Big Data Cluster architektúra
Az SQL Server Big Data Cluster (BDC) Kubernetes (K8s) container platformon fut egyelőre (még csak) Linux-os környezetben. A Kubernetes lesz a felelős a BDC állapotáért, a Kubernetes építi fel és konfigurálja a node-okat illetve rendeli hozzá a pod-okat a megfelelő node-okhoz, majd monitorozza a cluster-t.
De kezdjük az elején, így néz ki első ránézésre:
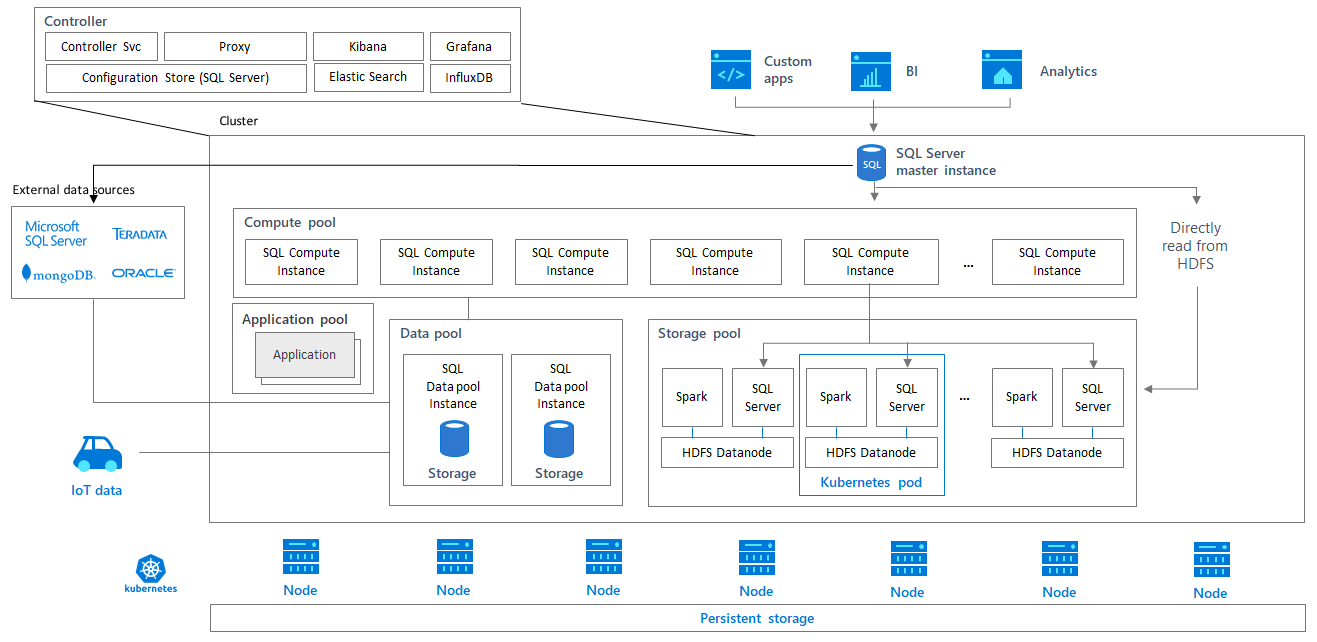
A könnyebb hivatkozás végett megkülönböztetünk nagyobb logikai egységeket. Ezekről most csak rövid áttekintést írok, tekintve, hogy az egyes egységek funkcionalitásban már önmagukban túlmutatnak több blogbejegyzés méretén is.
Controller
SQL Server 2019 Big Data Cluster (BDC) telepítésekor az első, amely létrejön az a Controller. A Controller végez minden interakciót a Kubernetes és a BDC között, felelős a telepítésért, majd az egész cluster működéséért, és a cluster biztonságáért. A Controller-ben kapnak helyet a cluster szintű szolgáltatások is, mint pl. a Grafana és Kibana. A Grafana egy grafikus dashboard-ot kínál a cluster aktuális állapotáról, pl. CPU-, memóriahasználat, jó néhány wait statisztika és még számos egyéb teljesítménymutató, míg a Kibana szintén egy grafikus felületen egyfajta log aggregátorként működik, és akár viszonylag összetett kifejezésekre is kereshetünk benne.
SQL Server Master Instance
A Big Data Cluster „agya és lelke”. Az SQL Server Master Instance, amely egy teljes körű SQL Server (már ami Linux környezetben elérhető), amely bármilyen jellegű workload-ra skálázható, legyen az OLTP rendszer, HTAP (Hybrid transaction/analytical processing), Data Warehouse vagy akár Machine Learning-re optimalizált szerver. A Data Virtualizáció és számos szolgáltatásnak a kiindulási pontja, ahogy egy belépési pont is a kliensprogramok számára.
Compute Pool
A Compute pool szolgáltatja a számítási kapacitást a BDC számára. Nagyjából a Polybase Scale-out Group szolgáltatást nyújtja, de cluster szinten és leginkább az "adat virtualizálás"-ban (data virtualization) vesz részt.
A data virtualization technológia lényege, hogy a Polybase technológiát kihasználva le tud kérdezni "külső" adatforrásokat (external) anélkül, hogy mozgatnánk vagy másolnánk az adatokat.
A BDC-n belül is data virtualizációval történik az egyes egységek összekapcsolódása. Például Master Instance-on futtathatunk olyan lekérdezést, amelyben "összejoinolhatunk" egy ott lévő relációs táblát egy, a HDFS-en tárolt file-ra definiált external table-lel, és akár mindehhez pl. egy külső Oracle adatbázis táblájára definiált external table-t is hozzávehetünk.
Storage Pool
A Storage Pool reprezentálja a HDFS cluster-t. Itt többek között az Apache Hadoop megfelelő verziója lett integrálva. Telepítéstől függően ide kerül a Spark is (CTP 3.1-től külön Spark Compute Pool is telepíthető). Az itt lévő SQL Server-ek csak a belső működést segítik.
Data Pool
A BDC egyik legegyszerűbben használható, de koncepcionálisan mégis szerintem az egyik legbonyolultabb eleme a data pool, úgyhogy erről most többet írok. Technikailag data mart jellegű ”hely”, de hogy Bob Ward-ot idézzem inkább amolyan data cache féle, amely a Polybase-es external table féle lekérdezésekre van optimalizálva. Nem véletlen, hogy ennek a rétegnek az elérése, illetve az itt lévő adatbázisok és táblák létrehozása eleve a Master Instance-ból történik external table-kel.
A Data Pool-ban a podok számától függően egy vagy több SQL Server (On Linux) fut, amely abszolút az olvasási sebességre optimalizált.
Jelenleg kétféle adattárolási mód támogatott: Replicated és Round Robin. Az előbbi esetében minden egyes SQL Server Instance-ban létrejön a másolata a táblának, az utóbbi amikor a tábla elosztottan tárolódik a data pod-okban lévő SQL Server instance-okon. Mindezt megtoldva azzal, hogy a data pool-ban létrejövő táblákon automatikusan létrejön egy clustered columnstore index is, ezekkel is optimalizálva az olvasást.
Mire használható? Például előre kiszámított aggregációk tárolására, amely származhat relációs adatforrásból (Master Instance, külső Oracle, SQL Server stb. adatbázis), vagy HDFS-ről is pl. az utolsó 6 hónap aggregációja. Vagy egyszerre akár mindből is. De tárolhatjuk itt a data scientist-eknek vagy Machine Learning tréninghez az adatokat is és még sorolhatnám.
Application Pool
Ide kerülhetnek az alkalmazások, jelenleg R és Python app-ok, MLeap és SSIS támogatott. Az itt lévő pod-ok nem előredefiniáltak, hanem alkalmazásonként egy sepc.yaml file-ban felparaméterezhetőek és skálázhatóak. Ezt a spec.yaml-t használja specifikációként a Controller, hogy a Kubernetes-től igényelje a kívánt szolgáltatást.
HDFS Tiering
(Bár még nem sikerült beszereznem azt az BDC Architecture ábrát, amelyen rajta van a HDFS Tiering, de azért megemlítem :-) )
A HDFS Tiering-gel Big data Cluster-en kívüli HDFS rendszereket tudunk bemountolni a rendszerünkbe. Jelenleg Azure Data Lake Storage Gen2-t és az Amazon S3-at támogatja. A célja egyszerű, szeretnénk más data lake által tárolt adatokkal dolgozni, anélkül, hogy integrálnánk mindet, a megoldás HDFS Tiering. Ismét a data virtualizáció témaköre. Leegyszerűsítve, mountoláskor az elérendő külső folderek és file-ok metaadatai kerülnek letárolásra a BDC-ben, és ha egy query - lehet SQL vagy SPARK is - hivatkozik rá, csak abban az esetben másolódnak át a kért adatok a BDC-re, mégis úgy használható mint egy lokálisan tárolt HDFS adat a cluster-ben.
Skálázhatóság
A Big Data Cluster telepítése során az egyes logikai egységekhez tartozó pod-okat igény szerint hozhatjuk létre.
Ha több számítási kapacitás kell, több compute és spark pod-ot definiálunk. Ha nagy mennyiségű félig strukturált vagy nem strukturált adathalmazt (pl. fájlokat, képeket stb.) tárolnánk HDFS-en, akkor több storage pod-dal érdemes számolni. De dönthetünk úgyis, hogy jellemzően relációs adatokat kezelünk, ezért a storage pod-ok számát minimálisra vesszük. Vagy mondhatjuk, hogy "minden is kell", azaz kell a relációs engine, a HDFS, a Machine Learning Spark-ostúl és mindenestül, azt is képes kezelni a cluster.
Mindez két JSON file-ban konfigurálható a telepítés előtt.
Machine Learning
Már-már kikerülhetetlen téma manapság a Machine Learning. A GDPR miatt a Microsoft koncepciója az ún. In‑Database Machine Learning, amely azt jelenti, hogy Machine Learning teljes folyamatát (adatleválogatás, adatok trainelése, training model letárolása és portolhatóvá tétele stb.) a rendszeren belül tartja, azaz nem kell kivinni az adatokat a cluster-ből.
Természetesen a Big Data Cluster-ben is van Machine Learning, kétféle is:
- A BDC Master Instance alapértelmezetten egy Machine Learning Services-sel érkezik, azaz nem is kell külön installálni. Ez a „klasszikus” Microsoft SQL Server ML, és a szokásos external script-ben futtatható R vagy Python scriptekkel használható.
- A HDFS adatokra (és a relációs adatokra is akár) használhatunk SPARK ML-t is.
Big Data Cluster eszközök
A Big Data Cluster-hez - mint jó értelemben vett technológiai kavalkádhoz - számos programot használhatunk a különböző funkciók illetve az egyes egységek kezeléséhez, menedzsmentjéhez. Ezekből a teljesség igénye nélkül az általam leginkább használtakat sorolom fel.
- Azure Data Studio (ADS): Az Big Data Cluster használatához az elsődleges cross-platform (Windows, Linux, macOS) adatmenedzsment eszköz.
Míg az Azure Data Studio jellemzően a BDC funkcionalításokra koncentrál, vannak kifejezetten a Kubernetes/BDC Cluster/SQL Server menedzsmentre használható eszközeink is.
- azdata: Command-line tool a Big Data Cluster telepítéséhez és menedzseléséhez.
- kubectl: Command-line tool a Kubernetes cluster-hez
- SQL Server Management Studio (SSMS) : Ezt talán nem kell bemutatnom ;-)
- Visual Studio Code: A Kubernetes extension-t nagyon ajánlom...
Természetesen vannak további eszközök is, mint az Azure CLI, ha AKS-t használsz, vagy az mssql-cli illetve a curl, amelyekre szükség lehet még, de én leggyakrabban a fenti eszközöket használom.
Itt a vége?
Közel sem, igazából még rengeteget lehetne írni. A Big Data Cluster folyamatosan fejlődik, bővülnek a funkciók. Ami azt illeti kifejezetten „never ending story”, szóval terveim szerint még visszatérek pár blogbejegyzéssel :-)